ISC20 Student Cluster Competition结束了,冠军是中国科大,亚军是南非超算,第三名是清华,第四名是南阳理工,我们爱丁堡大学(TeamEPCC)得到了第五名,结果差强人意,我负责的项目Elmer/Ice也是第五名,西班牙小哥负责的BERT得到第四,另外一个西班牙小哥负责的coding challenge和tinker也是第四,其他两位同学成绩不是很理想,那就简单写一下本次比赛的一些心得吧。先上一张我们的团队图片以及疫情期间在家打比赛的照片。



首先简单介绍一下这个比赛,这个比赛全称是国际超算比赛(ISC),每年举办一次,基本都是在德国举办,2020年的比赛应该是在法兰克福举办,但是突然爆发的COVID-19让这场线下比赛改为了远程比赛,这就意味着每支队伍不再需要单独构建自己的超算集群,这样的话比赛的质量就打了一点折扣了,因为这个比赛的一个很重要的task就是构建自己的超算集群,然后在集群上跑Benchmarking和HPC Applications,谁的速度快,准确性高便取胜。
远程比赛也就意味着committee会提供一个shared cluster,我原本以为committee会自己搭建比赛集群或者使用德国或欧洲的超算集群来作为比赛的平台,出乎我的意料,作为德国的超算比赛,居然用了一个新加坡的集群(NSCC),不知道是不是商业赞助,更加坑爹的是,这个比赛集群是个巨坑,细节后续再讲。
因为是shared cluster,LINPACK, HPCG, and HPCC等这些Benchmarks就不会再作为比赛项了,于是组委会将浙这些项目改成了Gromacs,Tinker-HP等,同时今年新增了一个coding challenge项目。我们比赛的队伍有五个人,不同于其他队伍都是本科生(其他队伍都比我们人多一点),我们的队伍都是HPC/HPC-DS专业的研究生,每个人负责一个单独的项目,我负责的是Elmer/Ice,一个冰川建模软件。疫情期间,学校关闭了,我们五个人只有我和保加利亚的小哥留在爱丁堡,两个西班牙的小哥回国了,塞浦路斯的小姐姐也回去了,因此我们的交流时间并不多,基本上是每个人做自己的东西。
比赛开始后,我们都要通过VPN连上新加披的集群NSCC,这个是南阳理工和新国立两间学校在使用的集群,VPN连接上之后,速度真的不敢恭维,很多时候速度会巨慢,然后提交了PBS jobs后就会进入无穷等待队列,我的一个任务等了3天。。然后等来的结果是job killed walltime exceeded limit,我的walltime设置的是2小时,后来我将其不断调整甚至到12小时,依旧报这个错误,我确信这是集群的问题,因为我在archer上最多20几分钟就可以跑完这个程序。比赛过半之后,我的几个任务可以又报出错误:job killed: mem job total exceeded limit,我确定和我的脚本没有关系(select=4:ncpus=24:mpiprocs=24:ompthreads=1:mem=96gb),是集群资源不够,没办法,除了傻等,其他都做不了。比赛过了大半,我的三个节点的程序可以跑出结果了,感谢党,这个集群居然还有资源够用的时候,但是四个节点的任务一直还是不行的,我尝试过跑GPU+CPU节点(但是组委会说过,Elmer/Ice不需要寻找GPU节点方案,我这里只是尝试),或者通过申请四个节点,但是每个节点不跑满的方式,可是全部fail,除了等待真的没有其他办法,当时我基本上决定要提交三个节点的成绩,可是在最后一天的时候,我看到邮件通知,我的四个节点任务正常结束,我看了下时间,比三个节点的要好些,于是保存了一份,作为提交结果,我不清楚NSCC的队列调度方式和资源分配方式,反正我的大部分时间都在等待上,真的无力吐槽。
再讲一下Elmer/Ice的编译和优化,这个项目比较大,主要使用C/C++/Fortran来编写,需要交叉编译(使用的Cmake编译),同时依赖大量的第三方类库例如MMG,HDF5,NetCDF等,在比赛之前我们需要在自己学校的超算平台Cirrus编译练习的,但是这平台被黑客攻击用来挖矿,只能选择另外一个架构比较老旧的平台Archer,不巧的是,它也被攻击了,好吧,只能等待,好在比赛开始前几天,Archer修好了,开始在Archer上编译,我尝试过GCC,Intel compiler,PGI等,只有GCC成功,Archer上Intel的版本太低,程序有个BUG必须要高一点版本,本打算自己装一个Intel compiler,但是时间太紧,直接上比赛集群练习了。到了NSCC上,我使用Intel编译的,NCSS的Intel最新版本是19版本,安装编译虽然遇到了很多坑,这里有个很诡异的事情,就是环境变量的问题,当我加载了众多模块后
module load scotch
module unload composerxe/2016.1.150
module load intel/19.0.0.117
module load netcdf/intel19/netcdf-f-4.4.5
module load openmpi/intel/1.10.2
module load cmake/3.14.4
module load hdf5/1.10.5/intel19/parallel
module load netcdf/4.4.0/xe_2016/parallel
module load netcdf-fortran/4.4.3/xe_2016/parallel
这里Intel的版本因该是19,可是需要手动修改一下环境变量,否则Inte的版本会变成16
source /app/intel/xe2019/compilers_and_libraries_2019.0.117/linux/bin/compilervars.sh -arch intel64 -platform linux
编译的时候有还能多编译选项可以优化比如
-Ofast -fPIC -ipo -finline -align -xCORE-AVX2 -axAVX,SSE4.2 -mtune=haswell -L/opmpath/lib -lipmf -lipm
当然还有一个很重要的选项可以使用-pgo,这个会生成一个优化报告,编译的时候compiler会根据这个进行针对性优化。
比赛要求使用IPM来进行profiling,我当时不知道NSCC有安装这个,我还自己手动安装了IPM和ploticus。
对于优化来讲,其实能优化的地方不多,除了代码和编译优化,还有一个地方就是SIF文件,也就是Elmer的配置文件
!%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
! You are allowed to change any EXISTING parameter entry
! in this file to tune your run
! just leave the residual output numbers as they are in
! order that log-file remains readable
!%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
! tolerance of block solutions (if you choose iterative)
$blocktol = 0.001
! max amount of block iterations (if you choose iterative)
$blockiter = 2000
! pre-conditioner of block matrices
$preblock = "ILU0"
! Nonlinear system settings
Nonlinear System Max Iterations = 50
Nonlinear System Newton After Iterations = 5
Nonlinear System Newton After Tolerance = 1.0e-02
!Nonlinear System Relaxation Factor = #2.0/3.0
! Default is [1 2 3 4]
! Block Structure(4) = Integer 1 1 1 2
! Block Order(4) = Integer 1 2 3 4
! Linear System Scaling = False
! Linear system solver for outer loop
!-----------------------------------------
Outer: Linear System Solver = "Iterative"
Outer: Linear System Iterative Method = GCR
Outer: Linear System GCR Restart = 250
Outer: Linear System Residual Output = 10 ! please, leave that one to keep output readable
Outer: Linear System Max Iterations = 500
Outer: Linear System Abort Not Converged = True
Outer: Linear System Convergence Tolerance = 1e-05
block 11: Linear System Convergence Tolerance = $blocktol
block 11: Linear System Solver = "iterative"
block 11: Linear System Scaling = false
block 11: Linear System Preconditioning = $preblock
block 11: Linear System Residual Output = 100 ! please, leave that one to keep output readable
block 11: Linear System Max Iterations = $blockiter
block 11: Linear System Iterative Method = idrs
block 22: Linear System Convergence Tolerance = $blocktol
block 22: Linear System Solver = "iterative"
block 22: Linear System Scaling = false
block 22: Linear System Preconditioning = $preblock
block 22: Linear System Residual Output = 100 ! please, leave that one to keep output readable
block 22: Linear System Max Iterations = $blockiter
block 22: Linear System Iterative Method = idrs
block 33: Linear System Convergence Tolerance = $blocktol
block 33: Linear System Solver = "iterative"
block 33: Linear System Scaling = false
block 33: Linear System Preconditioning = $preblock
block 33: Linear System Residual Output = 100 ! please, leave that one to keep output readable
block 33: Linear System Max Iterations = $blockiter
block 33: Linear System Iterative Method = idrs
block 44: Linear System Convergence Tolerance = $blocktol
block 44: Linear System Solver = "iterative"
block 44: Linear System Scaling = true
block 44: Linear System Preconditioning = $preblock
block 44: Linear System Residual Output = 100 ! please, leave that one to keep output readable
block 44: Linear System Max Iterations = $blockiter
block 44: Linear System Iterative Method = idrs
这里面主要能改的就是一下tolerance,pre-conditioner,Iterative Method,对于pre-conditioner来讲可以使用ILU0,ILU1,ILU2,但是精度越高意味着内存和时间去求更大,虽然迭代次数可能会减少,因为选择ILU0。
ILU(0)分解预处理技术,对原系数矩阵做无任何额外非零元填充的ILU的分解,预处理速度较快。大规模的数矩阵一般具有稀疏性,ILU(0)分解不注入非零元, 能够有效保持系数矩阵的稀疏性,因此这一预处理方法适用于系统系数矩阵。而不完全LU分解中的其他两类方法 ILU(1)和 ILU(2),虽然相较于 ILU(0)能够一定程度上提高预处理效果、减少方程求解的迭代次数,但是这两种预处理方法速度较慢,且均需要注入非零元,破坏系数矩阵的稀疏性,在稀疏矩阵的乘法、内积等运算中显著加大计算量,降低计算的效率。
对于Iterative Method有很多选择比如
* CG
* BiCGSTAB(Biconjugate gradient stabilized method)
* Jacobi
* IDR(s)
对于IDR和BiCGSTAB的比较:
IDR(1) ≈ IDR is equally fast but preferable to the closely related Bi-CGSTAB, and that IDR(s) with s > 1 may be much faster than Bi-CGSTAB. It also turned out that when s > 1, IDR(s) is related to ML(s)BiCGSTAB of Yeung and Chan, and that there is quite some flexibility in the IDR approach
对于共轭梯度:
共轭梯度法收敛的快慢依赖于系数矩阵的谱分布情况,当特征值比较集中,系数矩阵的条件数很小,共轭梯度方法收敛得就快。“超线性收敛性”告诉我们,实际当中,我们往往需要更少的步数就能得到所需的精度的解。
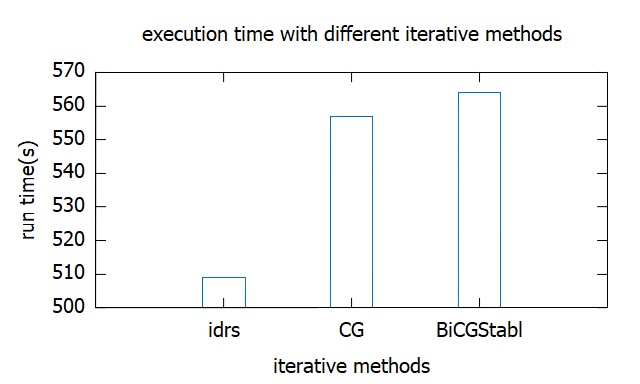
我这里对主要的方法做了一张图来分析其执行时间,最终选择IDR
最终运行后得到的profiling截图如下


最终结果图

给出建议
We can see from the graph that MPI_Recv took a lot of time. First, it is a blocking method and receive a message in a blocking fashion.Also, for the the cross-node communication, it would bring the addtional costs.
In this case, MPI_Irecv could be employed to reduce the waiting time. It does not blocked until the message is received.
As for the sending message, the MPI_Bsend had been used, which is is the asynchronous blocking send. For a performance perspective, we could consider using non-blocking communication methods such as MPI_Ibsend, it is the asynchronous non-blocking send.

当然这个项目的可优化之处很多,我这个只是敷衍面试写的几句话,首先这个项目可以使用GPU版本,同时对于进程的分配其实可以考虑单进程多任务。当然还可以加入ML的东西,不过貌似开发者已经开始考虑这一点了。
说一下面试,面试其实有两次,比赛期间有一次主要是meet team,视频在YouTube上,后一次面试是技术面试,是一个presentation,我们自己每个人大约讲5分钟关于自己的项目,评委会针对性的问技术问题,问题大都是和项目相关的,最终我们的面试成绩是第六,也不是很理想。